

В современном мире генерируется огромное количество информации, при сборе которого открывается большой потенциал в использовании этой информации для улучшения жизни как отдельных личностей, организаций, городов, так и целых областей науки. В данной работе рассматривается анализ набора больших данных, который может быть применен для различного улучшения состояния жизни, и способы работы с ним.
Изо дня в день в век интернета и информационных технологий действия человека, какими бы они мелкими и незначительными не были, не остаются незамеченными. Поисковой запрос, обычная прогулка с телефоном в руках с использованием GPS, любая покупка в магазине, прослушивание музыки или установка приложения – каждое действие генерирует новый поток информации. Учитывая количество живущих на Земле людей, информации накапливается очень много. Еще больше данных производят машины, работа которых либо полностью основана на IT-технологиях, либо предполагает оцифровку физических или химических процессов, как, например, это происходит на нефтехимических предприятиях [1, 2, 3].
В итоге мировой объем оцифрованной информации растет по экспоненте. Так, к 2003 году было накоплено 5 эксабайт данных (1 ЭБ = 1 млрд гигабайт = 1018 байт), к 2008-му – 0,18 зеттабайта (1 ЗБ = 1021 байт), к 2011 году – 1,76 зеттабайта, к 2017-му – порядка 10 зеттабайт (1022 байт) по данным российского IT-холдинга IBS.
Однако данные получают какую-либо ценность, только если сохраняются и анализируются. По оценке IBS, сегодня ценность имеет лишь несколько процентов генерируемых данных, а по расчетам аналитиков американской корпорации Dell ЕМС, используется лишь 3 % от потенциально полезной информации. Дело в том, что существовавшими еще 10–15 лет назад методами с таким объемом данных справиться было невозможно [1].
Сегодня технологии big data на постоянной основе используются в бизнесе, медицине, экономике и прочих различных отраслях В данной работе на основе набора данных, описывающего состояние воздуха в мировом масштабе, мы проводим с помощью специальных инструментов анализ данных.
Основная часть (Результаты исследований)
Используя инструменты анализа больших данных, необходимо было выполнить следующие задачи:
Анализ и описание состава набора данных, полей и преобразование, если необходимо, данных.
Поиск зависимостей, корреляций и гипотез в данных, построение соответствующих запросов, построение результирующих графиков и анализ результатов.
Набор данных
Набор данных, взятый для данной работы, является «Real-time Air Quality» и представляет собой данные о качестве воздуха из 5490 локаций в 47 странах[4]. Набор включает в себя актуальные данные, которые обновляются по сей день по всему миру. Скриншот данных можно наблюдать на рис. 1.

Рис. 1. Данные Real-time Air Quality
Рис. 2. BigQuery

Рис. 3. Данные по всему миру
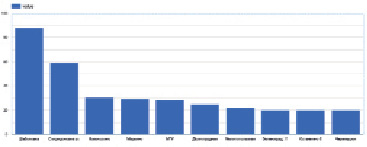
Рис. 4. Данные по России

Рис. 5. Данные по загрязненным локациям
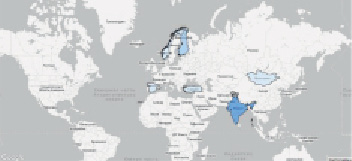
Рис. 6. Данные на мировой карте

Рис. 7. Данные за 20 лет
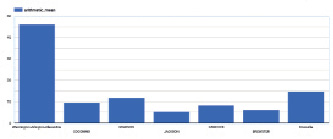
Рис. 8. Данные за 20 лет, визуализация
Для выполнения задачи и аналитической работы с данными, используется BigQuery. BigQuery – это RESTful веб-сервис для интерактивного широкомасштабного анализа больших наборов данных, расположенных в Google Storage [5]. Данный инструмент позволяет с легкостью обрабатывать аналитические запросы с помощью SQL языка, с помощью Студии данных визуализировать информацию в нужном нам виде. В данном веб-сервисе уже присутствуют различные наборы данных, от медицинских до банковских, позволяющие быстро начать работу по освоению понимания анализа больших данных. Существует там так же раздел для загрузки своих наборов данных с различным форматированием и разделением, позволяющим в два клика загрузить данные из файла в удобную для анализа таблицу. Скриншот интерфейса представлен на рис. 2.
Анализ данных
Известно, что PM10 (мелкие твердые частицы диаметром 10 микрон и менее) вызывают заболевания и рак, что в 2012 году является причиной примерно 3 миллионов преждевре менных смертей во всем мире. Мы решили провести исследования на эту тему и посмотреть состояние концентрации конкретно в России, посмотреть актуальную информацию по самым загрязненным локациям на данный момент и так же рассмотреть статистику изменения качества на протяжении нескольких лет.
Данные по всему миру в табличном варианте представлены на рис. 3.
Данных конкретно по России немного, датчики снимают показания только столицы, но и тут можем наблюдать интересные результаты концентрации (рисунок ниже). Стоит отметить, что данные в наборе записаны официальным языком страны, из которой поступают данные, то есть на графике указаны локации именно так, как они записаны в датасете. Графический результат анализа представлен на рис. 4.
Страны с локациями с наиболее худшей ситуацией концентрации PM10 по последним данным.
Так же рассмотрим самые загрязненные локации на мировой картине.
Результаты запроса представлены на рис. 5.
Инструментарий BigQuery позволяет быстро визуализировать результаты на карте мира, пример представлен на рис. 6.
Так же набор данных позволяет посмотреть исторические изменения качества воздуха, но, к сожалению, только в Америке.
Посмотрим, какой из городов за 20 лет наиболее улучшил качество воздуха. Для этого используем параметр air_quality_difference, который при запросе автоматически вычисляет разницу между текущим состоянием и данными за 1990 год.
Результат запроса представлен на рис. 7.
Визуализированный результат запроса представлен на рис. 8.
За всё это время наилучший результат показал Вашингтон, что неудивительно, будучи столицей страны.
Заключение
Проанализированы актуальность направления больших данных и примеры использования, постановка задачи, описан используемый набор данный и инструментарий, который использовался для обработки и визуализации результатов запросов.
Проведен анализ данных и рассмотрено качество воздуха в различных районах и в различном времени.
Выбранный набор данных имеет потенциал в совместной работе с другими наборами, например, для реального сопоставления и подтверждения связи качество воздуха и проявления различных заболеваний, в отрасли туризма, для поиска наиболее выгодных и оздоровительных мест для отдыха и для настройки цен в зависимости от комфорта и качества воздуха в данных местах, для здравоохранения для поиска причины загрязнения и анализа эффективности уже предпринятых или только планируемых мер для улучшения качества воздуха и влияние на ментальное и психическое состояние населения в различных регионах с различным количеством концентрации определенных веществ в воздухе, для экономики, чтобы посмотреть влияние качества воздуха на продуктивность рабочего населения и производства в целом.
Библиографическая ссылка
Гуреева М.С. АНАЛИЗ НАБОРА ДАННЫХ О КАЧЕСТВЕ ВОЗДУХА // Материалы МСНК "Студенческий научный форум 2026". 2021. № 9. С. 70-74;URL: https://publish2020.scienceforum.ru/ru/article/view?id=513 (дата обращения: 01.07.2026).