

Введение и постановка задачи
Случайные числа нашли широкое применение в различных областях, включая науку, технику, экономику, социологию, медицину и педагогику [1-4]. Их использование особенно ценно для моделирования явлений, трудных или невозможных в реальной практике. Примерами служат исследования взаимодействия элементарных частиц, операции в хаотичных условиях аэропорта, и прогнозирование развития человеческой цивилизации.
Случайность играет ключевую роль в принятии стратегических решений и проявляется в музыке и графических изображениях. В этом контексте, генерация случайных чисел становится важным элементом в прикладной математической статистике, особенно при работе с выборками [5,6]. Это имеет применение в методе Монте-Карло, имитационном моделировании [7], математическом моделировании [8] и др.
Генераторы случайных чисел с равномерным распределением получили широкое распространение [1] и служат основой для получения чисел с различными распределениями, включая нормальное [2,4,9]. Анализ возможности генерации нормального распределения имеет практическое и теоретическое значение, и именно этой проблеме посвящена настоящая работа.
Анализ последних исследований и публикаций
Самый простой метод основан на использовании предельной теоремы А.М. Ляпунова [9]. Рассмотрим множество случайных чисел с равномерным распределением на отрезке [0; 1]: u1, u2,..., un. Вероятность того, что случайная величина Х = (u1 +u2+... +un) / √(n/12) при n, стремящимся к бесконечности, будет меньше значения х, соответствующего нормальному распределению, определяется функцией Лапласа
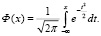 (1)
(1)
Для генерирования нормально распределённых чисел рекомендуется брать значение n, равным 6 или 12. Недостатком метода является довольно большое отклонение вычисленных значений Х, находящихся “на хвостах распределения” [10]. На практике чаще обращаются к методу, разработанному Д. Боксом, М.Мюллером и Д. Марсальей, и другим методам [1, 10, 11]. Все предлагаемые алгоритмы обеспечивают преобразование чисел с равномерным законом распределения в нормально распределённые. Современные программные средства (например, Matcad, Visual C++ и другие) позволяют решать подобную задачу с использованием стандартных программ. В связи с раннее указанным недостатком преобразования на основе предельной теоремы А. М. Ляпунова [9] рассмотрим только три алгоритма генерирования нормально распределённых чисел:
- метод полярных координат Бокса-Мюллера-Марсальи [1],
- метод полярных координат Бокса-Мюллера [11],
- стандартные программные средства из среды программирования Visual C++ [12].
Цель выполнения работы и постановка задачи
Цель работы является проведение сравнительного анализа различных методов преобразования чисел с равномерным распределением в случайные числа, подчиняющиеся нормальному закону, формула (1). Для достижения цели было необходимо решить следующие задачи:
- расписать алгоритм преобразования чисел с равномерным распределением в случайные числа, подчиняющиеся нормальному закону (1);
- выбрать критерий для проверки гипотезы о соответствии преобразованных случайных чисел нормальному закону;
- разработать расчётную программу в среде программирования Visual C++ для оценки проведения сравнительного анализа результатов, полученных различными методами;
- провести тестовые испытания.
Результаты работы
Алгоритм полярных координат Д. Бокса, М. Мюллера и Д. Марсальи, (в дальнейшем метод БММ), изложен в работах [1, 10]. Он предусматривает пошаговое выполнение следующих операций.
1. С помощью генератора равномерно распределённых чисел на отрезке [0;1] получают два случайных независимых числа r1 и r2.
2. Вычисляется значение параметра
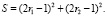
3. Если S ≥ 1, повторяется операция в первом пункте.
4. Рассчитываются два числа
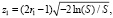
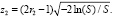 (2)
(2)
Формулы (2) обеспечивают получение двух независимых и нормально распределённых чисел z1 и z2 с дисперсией, равной 1, и нулевым математическим ожиданием.
Видоизменённый алгоритм Д. Бокса и М. Мюллера [11], (в дальнейшем метод БМ). На первом этапе получают два независимых случайных числа r1 и r2, которые равномерно распределены на отрезке [0;1]. Далее они преобразуются в два нормально распределенных значения z1 и z2 по формулам Бокса-Мюллера:
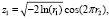
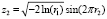 . (3)
. (3)
Формулы (3), как и формулы (2), обеспечивают получение двух независимых и нормально распределённых чисел z1 и z2 с дисперсией, равной 1, и нулевым математическим ожиданием, т.е. в первом приближении соответствуют нормальному распределению, определяемую функцией Лапласа (1).
Для получения нормального распределения с другим среднеквадратическим отклонением σ и другим математическим ожиданием а необходимо значения z1 и z2 умножить на σ и к полученным величинам прибавить а.
Метод генерирования нормально распределённых чисел в среде программирования Visual C++ [12], (далее метод Normal_distribution).
При реализации нормально распределённых чисел в среде Visual C++ в программе необходимо подключить библиотеку <random>, которая содержит различные генераторы. В разрабатываемой программе использовался генератор random_device, который в отличие от стандартного генератора rand обладает большим диапазоном. Многократный вызов функции
normal_distribution<double>norm(0,1)
обеспечивает генерирование нормально распределённых случайных чисел с нулевым математическим ожиданием и единичным среднеквадратическим отклонением.
Проверка гипотезы о соответствии случайных чисел закону нормального распределения. Проверка гипотезы о выполнении закона нормального распределения проводилась с использованием χ2-критерия Пирсона. Выборки объёмом n = 100 формировались с использованием трёх вышеописанных методов среднеквадратическим отклонением σ и другим для математического ожидания а = 0 и среднеквадратического отклонения σ = 1. Поскольку большая часть случайных чисел лежит в пределах (3-6)σ, учитывались только значения на отрезке [-4,+4], где находится более 99,99% от общего количества [13].
Критерий Пирсона обладает v = s – 3 степенями свободы, где s – число интервалов. Критическая область определяется неравенством χ2>χ2кр(α,v), где α – уровень значимости. Критическое значение χ2кр для α = 5%, v = 6 равно 16,8 [3]. При χ2<16,8 гипотеза о нормальности выборки принимается, в противном случае отвергается. Результаты обработки статистических данных, полученных различными способами представлены в табл. 1 (метод БММ), табл. 2 (метод БМ) и табл. 3 (метод Normal_distribution).
Критерий Пирсона χ2 для данных табл.1 равен 9,622. Поскольку полученное значение меньше критической величины χ2кр=16,8 для 5%-го уровня значимости при 6 степенях свободы [3], то гипотеза о нормальности выборки в случае использования метода Д. Бокса, М. Мюллера и Д. Марсальи принимается.
Рассчитанныйкритерий Пирсона для данных табл. 2 равен 13.651. Полученное значение меньше критической величины χ2кр=16,8 в случае 5%-го уровня значимости при 6 степенях свободы [3]. Поэтому гипотеза о нормальности выборки, сгенерированной методом Д. Бокса и М. Мюллера, принимается.
Таблица 1
Результаты проверки гипотезы о соответствии случайных чисел, генерированных методом БММ, нормальному закону распределения: хi – середина i-го интервала, ni – количество сгенерированных чисел в i-м интервале, n’i – теоретическое значение случайных величин в i-м интервале
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
хi |
-3.56 |
-2,67 |
-1,78 |
-0,89 |
-0,00 |
0,89 |
1,78 |
2,67 |
3,56 |
|
ni |
0 |
1 |
6 |
20 |
33 |
24 |
13 |
3 |
0 |
|
n’i |
0.06 |
1 |
7.27 |
23.87 |
35.46 |
23.87 |
7.27 |
1 |
0.06 |
Таблица 2
Результаты проверки гипотезы о соответствии случайных чисел, генерированных методом БМ, нормальному закону распределения: хi – середина i-го интервала, ni – количество сгенерированных чисел в i-м интервале, n’i – теоретическое значение случайных величин в i-м интервале
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
хi |
-3.56 |
-2,67 |
-1,78 |
-0,89 |
-0,00 |
0,89 |
1,78 |
2,67 |
3,56 |
|
ni |
0 |
1 |
3 |
18 |
32 |
35 |
8 |
3 |
0 |
|
n’i |
0.06 |
1.03 |
7.48 |
24.54 |
36.46 |
24.54 |
7.48 |
1.03 |
0.06 |
Таблица 3
Результаты проверки гипотезы о соответствии случайных чисел, генерированных методом Normal_distribution, нормальному закону распределения: хi – середина i-го интервала, ni – количество сгенерированных чисел в i-м интервале, f(xi) – значение функции Лапласа в точке xi, n’i – теоретическое значение случайных величин в i–м интервале
|
i |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
хi |
-3.56 |
-2,67 |
-1,78 |
-0,89 |
-0,00 |
0,89 |
1,78 |
2,67 |
3,56 |
|
ni |
0 |
4 |
6 |
28 |
35 |
21 |
5 |
1 |
0 |
|
n’i |
0.06 |
1.03 |
7.48 |
24.54 |
36.46 |
24.54 |
7.48 |
1.03 |
0.06 |
Критерий Пирсона, вычисленный по формуле (4) для данных табл. 3, равен 11,065. Он намного меньше критической величины χ2кр=16,8 в случае 5%-го уровня значимости при 6 степенях свободы [3], что позволяет принять гипотезу о нормальности выборки, полученной в среде программирования Visual C++ методом Normal_distribution.
Выводы
Все представленные нам ранее методы генерации случайных чисел подчиняются Критерию Пирсону, что без условно нам говорит о их нормальности. Проведя анализ более точным является метод БММ, также очень хорошо себя проявил метод БМ, что касается метода Normal_distribution он конечно точнее чем метод БМ, но он не всегда точно срабатывает, иногда генерируются такие числа, что не подчиняются Критерию Пирсона. Метод Normal_distribution хоть и есть у него такой большой минус, есть также большой плюс это его простота использования, где вместо того что бы расписывать формулы как в ранее указаных методах можно просто написать команду и указать мат. ожидание и отклонение. То есть в качестве учебных целей для ознакомления, очень хорошо подойдет метод Normal_distribution. Но если надо для статьи, каких-нибудь вычислений, то тут хорошо себя покажут методы БМ и БММ.