

В современном цифровом мире проблематика в области информационной безопасности и управления событиями становится всё более сложной и разнообразной. Одной из ключевых трудностей является рост объёмов данных, требующих анализа для выявления угроз. Это ставит под угрозу эффективность традиционных систем безопасности, так как они зачастую не справляются с новым масштабом задач, приводя к пропуску важных инцидентов. С увеличением сложности кибератак требуется более глубокий анализ данных, что выходит за рамки возможностей стандартных автоматизированных систем и создаёт дополнительную нагрузку на специалистов, отвлекая их от более важных задач [8, c. 51-52].
В статье рассмотрены предложения по реализации продвинутых систем обработки естественного языка, таких как крупномасштабные языковые модели (LLM), которые могут быть использованы в рамках функционала SIEM-систем (Security Information and Event Management). SIEM-системы представляют собой комплексные системы, предназначенные для сбора, агрегации и анализа данных о событиях безопасности из множества источников. Они обеспечивают нормализацию данных, обнаружение аномалий, генерацию оповещений и предоставляют инструменты для визуализации и отчетности, что является важным элементом в стратегии обеспечения информационной безопасности.
LLM-модели, обученные на больших объёмах текстовых данных, обладают способностью к глубокому пониманию и интерпретации естественного языка, что позволяет им создавать осмысленные тексты, анализировать данные и поддерживать процессы принятия решений. В контексте SIEM-системы, LLM-модели обеспечивают эффективную обработку больших объемов данных, выявлять сложные угрозы и автоматизировать рутинные задачи, тем самым ускоряя обнаружение инцидентов и снижая нагрузку на специалистов [7, c. 59]. Это значительно повышает эффективность систем управления информационной безопасностью и помогает организациям адаптироваться к постоянно меняющемуся ландшафту кибербезопасности.
Нейросетевые технологии в решении задач автоматизации процессов классификации и реагирования на инциденты информационной безопасности
Наличие SIEM-системы в инфраструктуре автоматизирует процесс обработки событий. Автоматизация достигается при помощи алгоритмов нормализации и корреляции событий. События внутри SIEM-системы проходят следующую цепочку обработки (рис 1).
Модуль приема событий принимает события для дальнейшей обработки, а также добавляет метку со временем поступления события в SIEM.
Модуль нормализации событий реализует процедуру приведения необработанных событий к нормализованному виду в соответствии с заданными для источника и типа событиями правилами нормализации.
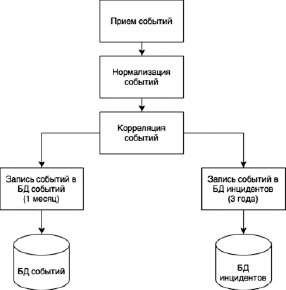
Рис. 1. Схема обработки событий информационной безопасности
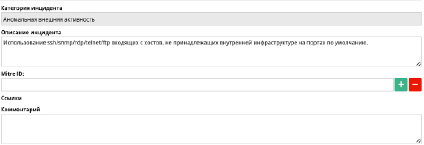
Рис. 2. Карточка инцидента
Модуль корреляции событий реализует анализ нормализованных событий согласно корреляционным правилам на наличие заданных цепочек взаимосвязей.
После обработки данными модулями события записываются в “БД событий” для их хранения (В нашем случае в течении месяца). Если какие-то события вызвали инцидент, то информация о них дублируется в “БД инцидентов” на долгосрочный период (В нашем примере в течение 3 лет) [1, c. 71].
Правила корреляции могут дополнительно обогащать информацию следующими типами данных: описание инцидента, информацию из перечня уязвимостей CVE. Карточка инцидента, представленная на рисунке 2, включает следующее описание инцидента в SIEM-системе: Категорию инцидента, информацию об инциденте, MITRE ID – уникальный идентификатор инцидента, соответствующий базе знаний MITRE ATT&CK (общедоступная база знаний действия нарушителя), а также комментарий к данному инциденту [8].
В представленном описании не в полной мере содержаться сведения для достоверной идентификации и приоритизации инцидента. Все эти данные добавляются на этапе создания правила корреляции и скорее относятся к заранее заготовленному шаблону, а не к произошедшему инциденту. Для дальнейшей обработки инцидента обязательно наличие высококвалифицированного специалиста первой линии. Этапы обработки инцидента при такой схеме представлены на рисунке 3 [5].
К основным задачам сотрудников первой линии (L1) относятся: категоризация, приоритизация и анализ событий ИБ. Данные шаги, как правило, занимают значительное время и практически не автоматизированы в типовой SIEM-системе, в том числе не обеспечивают необходимую степень достоверности [2, c. 3–7].
В свою очередь LLM-модели могут обеспечивать адекватное описание исходя из конкретных событий, которые вызвали инциденты, и давать комплексное описание, а также проводить приоритизацию, исходя из более глубоко анализа. С использованием LLM-моделей анализ событий реализуется следующим образом.
В SIEM-системе формируется запрос по API-интерфейсу к LLM-модели о возникшем инциденте ИБ (рис 4).
На основе LLM-модели производится анализ полученных событий, используя алгоритмы обработки естественного языка, результатом чего являeтся построение аналитических цепочек, соответствующих следующим возможным инцидентам: вирусным атакам, несанкционированному доступу, техническим сбоям и т.д.
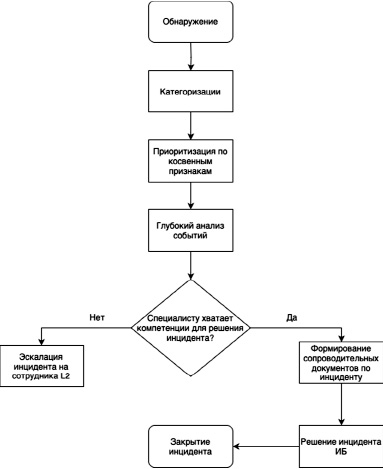
Рис. 3. Этапы обработки инцидента на первой линии
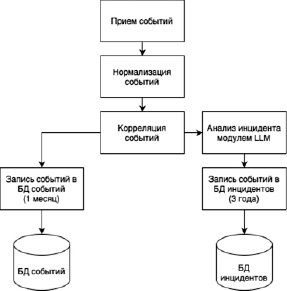
Рис. 4. Схема обработки событий информационной безопасности с использованием LLM-модели
В результате использования крупномасштабных языковых моделей в обработке инцидентов информационной безопасности, достигается более глубокий анализ каждого события и категоризация инцидентов. Это включает учет контекста, истории событий и их потенциального влияния на организацию, а также анализ поведенческих шаблонов, сравнение с известными угрозами и оценку вероятности ложных тревог. Такой подход позволяет более точно приоритизировать события, опираясь на уровень риска, влияние на бизнес-процессы и потенциальную угрозу для ключевых активов организации. [3, c 234-236].
Кроме того, использование LLM-моделей облегчает процесс подготовки подробных описаний каждого инцидента, включая контекст, вероятные причины и предложения по дальнейшим действиям. Эти описания обеспечивают специалистам первого уровня (L1) более оперативную обработку и глубокое понимание проблем, что способствует эффективному и оперативному реагированию. В дополнение, LLM-модели могут предоставлять рекомендации по реагированию на инциденты, основанные на лучших практиках и анализе предыдущих событий, что значительно ускоряет процесс принятия решений и повышает качество управления инцидентами. Таким образом, интеграция LLM-моделей в системы управления инцидентами позволяет повысить общую эффективность и точность процессов в области информационной безопасности [4].
Проанализируем инцидент: “Infotecs IDS: Попытка эксплуатации уязвимости ETERNALBLUE.” Описание которого представлена на рисунке 5.
На представленном рисунке демонстрируются результаты, полученные на основе крупномасштабной языковой модели. На основе анализа событий, были получены уточненные детали инцидента при помощи крупномасштабной языковой модели, превосходящие общее описание «Удаленного выполнения кода». С помощью LLM-модели были выявлены более конкретные и точные сведения о происходящих событиях. Кроме того, с использованием этой модели были разработаны специфические рекомендации по решению проблемы, связанной с конкретным IP-адресом, что демонстрирует её эффективность в предоставлении направленных и практических советов для ответа на инцидент. Результаты, показанные на рисунке 6, демонстрируют, как будет проходить расследование инцидента для инженера первой линии, исходя из полученных данных.
Данная интеграция позволяет существенно сократить время необходимое на обработку инцидентов, а также снизить нагрузку на специалистов второй линии за счет снижения необходимых компетенций для специалистов первой линии.

Рис. 5. Сгенерированное описание в карточке инцидента
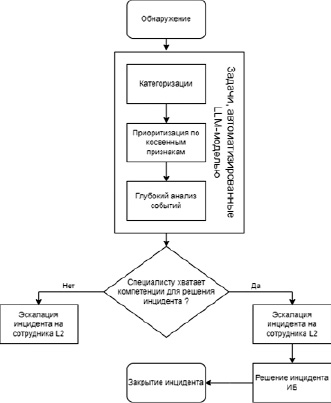
Рис. 6. Схема автоматизации обработки инцидентов
Исходя из рисунка можно сделать вывод, что осуществляется автоматизация следующих процессов: категоризация инцидентов, приоритизация инцидента, глубокий анализ событий информационной безопасности. Был реализован пилотный проект по внедрению LLM-модели в организацию, в результате которого были получены следующие результаты:
Среднее время решения инцидентов снизилось с 145 минут до 126 минут для специалистов первой линии.
Среднее количество ошибок LLM-модели в первую неделю составило около 4 ошибок на 10 инцидентов. Через месяц уровень выдачи ложных результатов анализа снизился до 2 ошибок на 10 инцидентов.
Приоритизация, инцидентов полученная в ходе анализа, полностью соответствует требованиям отдела информационной безопасности организации.
Количество инцидентов, закрытых аналитиками первой линии, увеличилось на 9%. Таким образом, обеспечено снижение поток инцидентов эскалированных на аналитиков второй линии.
Заключение
LLM-модель значительно расширяeт возможности SIEM-систем, обеспечивая более глубокий анализ данных и более точное обнаружение угроз. Интеграция LLM-моделей в SIEM-системы позволяет автоматизировать многие процессы, связанные с обработкой и анализом больших объемов данных, что повышает эффективность системы безопасности. Однако стоит использовать локальные LLM-модели для обеспечения конфиденциальности данных, производить непрерывное обучение и адаптацию этих моделей к изменяющимся условиям кибербезопасности.
Данная интеграция позволяет существенно сократить время, необходимое на обработку инцидентов, а также снизить нагрузку на специалистов второй линии за счет снижения необходимых компетенций для специалистов первой линии.